Music Genre Classification
Machine Learning | Audio Processing | Deep Learning | CNNs
This project focuses on building a model that classifies songs into musical genres based on their audio characteristics. Using deep learning and signal processing techniques, it demonstrates how raw sound data can be transformed into meaningful predictions.
Overview
To automatically classify music tracks into genres (e.g., rock, classical, hip-hop) using spectrogram-based feature representations and deep learning models, especially Convolutional Neural Networks (CNNs).
Goal
What I Did
Data Preprocessing
Used the GTZAN genre dataset, a benchmark dataset in audio ML.
Converted raw .wav files into Mel spectrograms, which visually represent audio frequency content over time.
Feature Representation
Treated mel spectrograms as grayscale images and resized them into consistent 128x128 formats for CNN input.
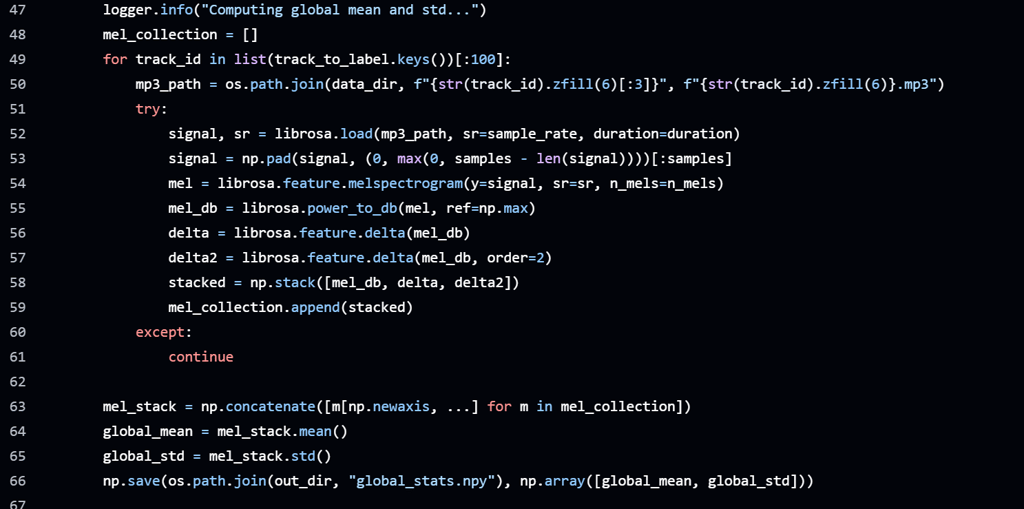

Generating Mel spectrograms
Model Development
Designed and trained a custom CNN to classify genres based on visual patterns in the spectrograms.
Applied dropout and normalization to reduce overfitting and stabilize training
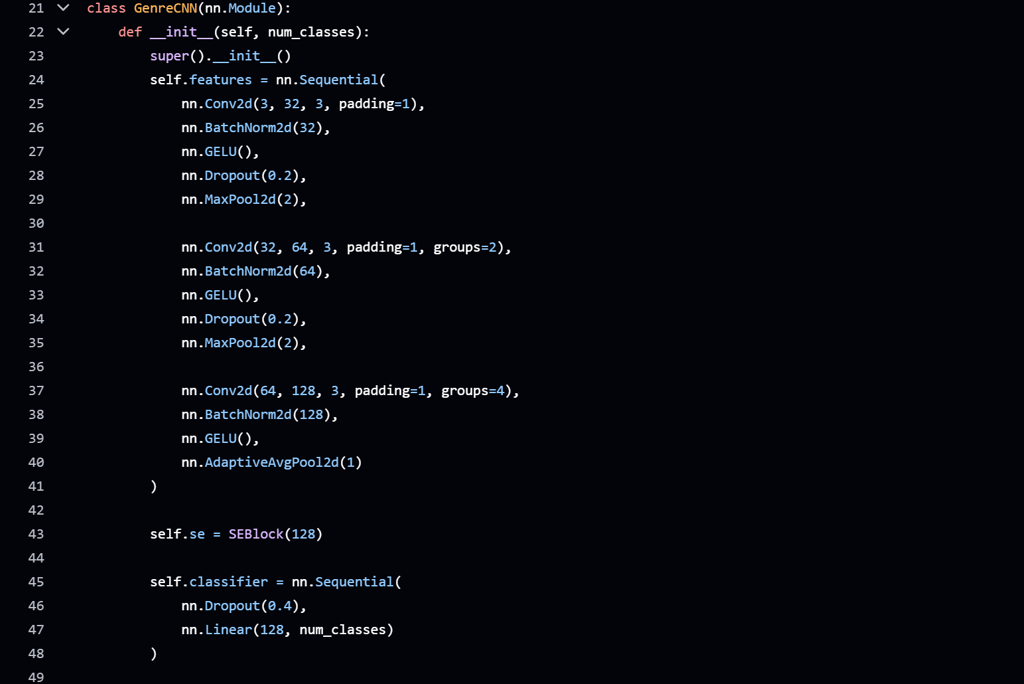

Custom CNN Architecture
Evaluation
Validation was used during training.
Measured performance using Accuracy, Precision, Recall, F1-score, and confusion matrices.
Visualized predictions and genre-wise misclassifications to interpret the model’s behavior.
Music Classification Confusion Matrix
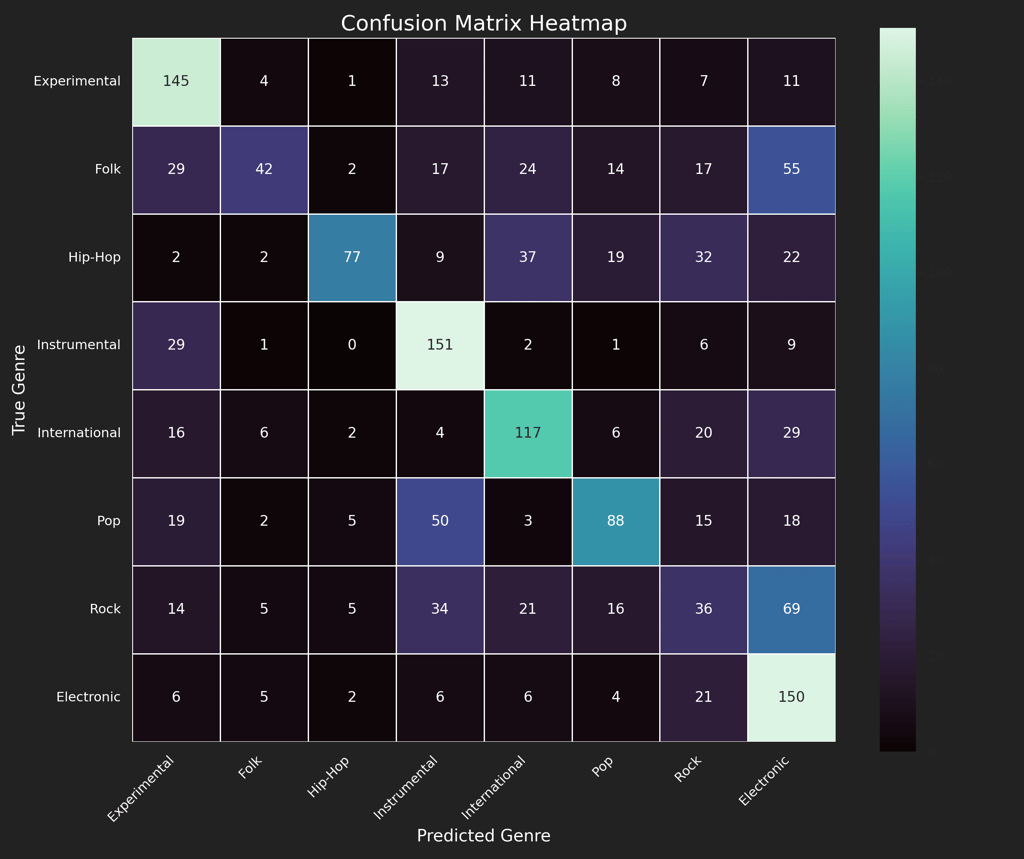
Performance Summary
Best Test Accuracy: 57.16% (Hip-Hop, Instrumental, International, and Pop genres)
Test Loss (Cross Entropy): ~1.43
Precision & Recall (Genre-specific):
Class 2 (Hip-Hop):
Precision: 51.5%
Recall: 77.0%
F1-score: 61.7%
Class 3 (Instrumental):
Precision: 80.7%
Recall: 60.8%
F1-score: 69.3%
Takeaways
Temporal features like delta and delta² helped the CNN capture subtle changes in audio textures.
Higher learning rates (0.01) led to faster convergence and better test accuracy compared to 0.001.
Genre confusion revealed musical overlaps—e.g., electronic and rock often misclassified due to similar instrumentation.
Tools and Technologies Used
Python, NumPy, Matplotlib
Librosa (audio processing)
TensorFlow / Keras (deep learning)
Scikit-Learn (classification metrics)
GTZAN Dataset
This project was completed as part of the course "DS-4213: Data Mining," taught by Dr. Bo Hui at the University of Tulsa in the spring 2025 semester.
My full code for this project can be found here on my GitHub.